pwd: /brain/cache/thoughts/deep learning, first epoch
Last Modified @ 2023-12-13
My First Epoch
whoami
Greetings, my name is Jericho Imperial, currently a 4th year CS undergrad who is addicted to the drug called “self-studying deep learning!” I’m technically a 4.5th year undergrad, because I am one class short even though my school let walk on stage and didn’t notify me of this issue beforehand, but anyways, welcome to my first “academic” blog about deep learning! Here’s a lot about me.
I come from an “I don’t know” background that I can say most CS students that don’t attend top tier schools come from in this generation. The “what does automata and assembly have to do with getting an internship” generation, also known as the “college is just a waste of time” generation. So, basically uninspired and lost in the field which they chose to commit to. Luckily, I’ve done two internships, in both of them I got to work on full stack and backend projects and thought, “this is it?” I was so-so with my baby steps into the industry which I still haven’t broke through yet, it wasn’t that exciting but I learned a lot and applied all of those skills to my current projects.
For my full stack internship, I remember one of my teammates wanted to create a machine learning application that creates a resume based on keywords (hold your horses). None of us knew anything about machine learning, and AI wasn’t a hot and global topic in the Summer of 2022 like it is today. Me, my other teammate, and our mentor all declined saying it’s out of our scope and continued with creating a full stack webapp. Honestly, it was out of scope since now I know a little bit more about this topic, what she wanted to do was create a generative AI that creates a resume based on keywords. Now looking back on it today, I really wish I was onboard with her to do it. I would’ve rather learn something exciting, new, and challenging and possibly fail due to time constraints, than to create a simple full stack webapp that many people have done before us.
How did I get into learning about deep learning? After my latest project at this time, I wanted to do something bigger and better. I wanted to create a website with a music visualizer as the background similar to milkdrop using three.js that’s connected to a winamp music player that you can control. This website would have a chat bot that would talk and act like my Cyberpunk Red table top role playing game character, nicknamed Chat. It was supposed to be a manifestation of a “what if this character I created was real” idea. For background, my character is basically a Vietnamese Austrailian girl who goes to raves and religiously listens S3RL and vlogs her actual physical self destroying end-game capitalism in the Cyberpunk world (very austrailian and y2k). I then prioritized on getting this chat bot to become a reality.

I researched about AI and how to “create” my own and stumbled on fine tuning as a way to possibly make models talk a certain way. I didn’t understand a single thing about how AIs work, what finetuning was, or even how to finetune. I’ve researched for a week and found people who did what I wanted to do, they made their fictional characters into literal AI that talked via Discord, they could even have conversations with each other! From there I knew my idea was possible, so I found resources to learn from the ground up and started with course.fast.ai.
expectations and reality
Before getting into this course, I had no idea what I was getting myself into. I felt like I was too dumb and thought I would suffer in the name of creating a fictional character. I thought there would be some sort of quantum math that I’ve never laid eyes on, and I thought I would need a $10,000 PC. I couldn’t of been more wrong, so far. I’m not that dumb, I have a cumulative 3.6 GPA. I wouldn’t suffer, I’m actually really enjoying learning about deep learning. I’ve been studying for 6-10 hours a day for 2 weeks now, I’m addicted. No quantum math is needed, just high school level calculus that you’ll see in this blog. I don’t need a $10,000 PC, yet, I’ve seen people who fine tune and train LLMs with 2+ RTX 4090s. Generally don’t need a beefed up PC to learn since I can just use platforms such as Google Colab and Kaggle! Although, a RTX 5090 in the future doesn’t seem so bad once I nail all of this down and get to their level though. It would be great for playing Cyberpunk 2077 and in max graphics and training LLMs!
As I’m writing this, I’ve completed lessons up to lesson 3, with lesson 3 being the hardest so far. The lecture isn’t hard to follow since Jeremy Howard does a great way of conveying the book, but the book material for lesson 3 is killer since it’s about the foundations of deep learning. Lesson 3 wraps everything up from lessons 1 and 2, then ties it in a bow, so that’s what I’ll be talking about!
what i’ve learned (lessons 1 and 2)
Disclaimer, I’m still learning, and I’m not 100% confident in everything I’m saying, so somethings could be wrong. This is also how I understand it!
Let’s start where I started, “what’s machine learning?” Machine learning is the process of a machine learning from itself. This is the most basic explanation. The more times it tries to learn, the smarter it gets! Just like a real life human brain!
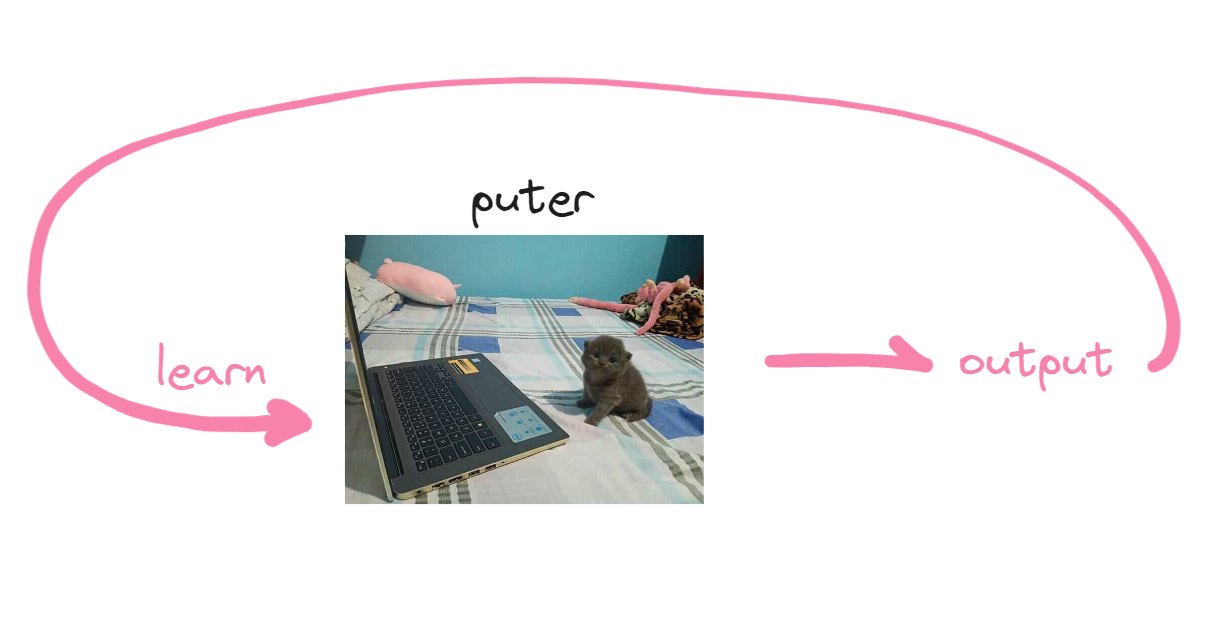
Let’s get more complex and specific as we go. Machine learning models usually want to learn how to do something right? So let’s see what one model would look like to identify if an image is a cat or not.
First off we need weights, weights are super important in machine learning because they’re the main way for the computer to decide for itself. In this case, it helps the computer decide if the input image is a cat or not.
Also, instead of saying “output,” we will reword it as a “prediction” since that’s what the computer outputs, predicting if the input image is a cat or not.

Now how do we make the computer learn? We can’t just send the prediction back, there’s nothing to learn from that. So that’s why we add loss which will be explained.
Computers don’t know what they’re dealing with and what things are. So that’s why we add labels for the computers to use. So now it will know if an input image is a cat or not.
Loss is a measure that determines if a computer is performing good in its predictions. Numerically, the lower the loss the better.
To explain the diagram, If we give the computer an image of a cat and it predicts it to be a dog somehow, we’ll say that the computer did a bad job and say “you silly goose, it was a cat!” That’s basically what loss does. Behind the scenes, the loss tells the computer how to better identify a cat, therefore updating the weights. Recall, the weights are main way a computer can decide for itself. The cycle continues.
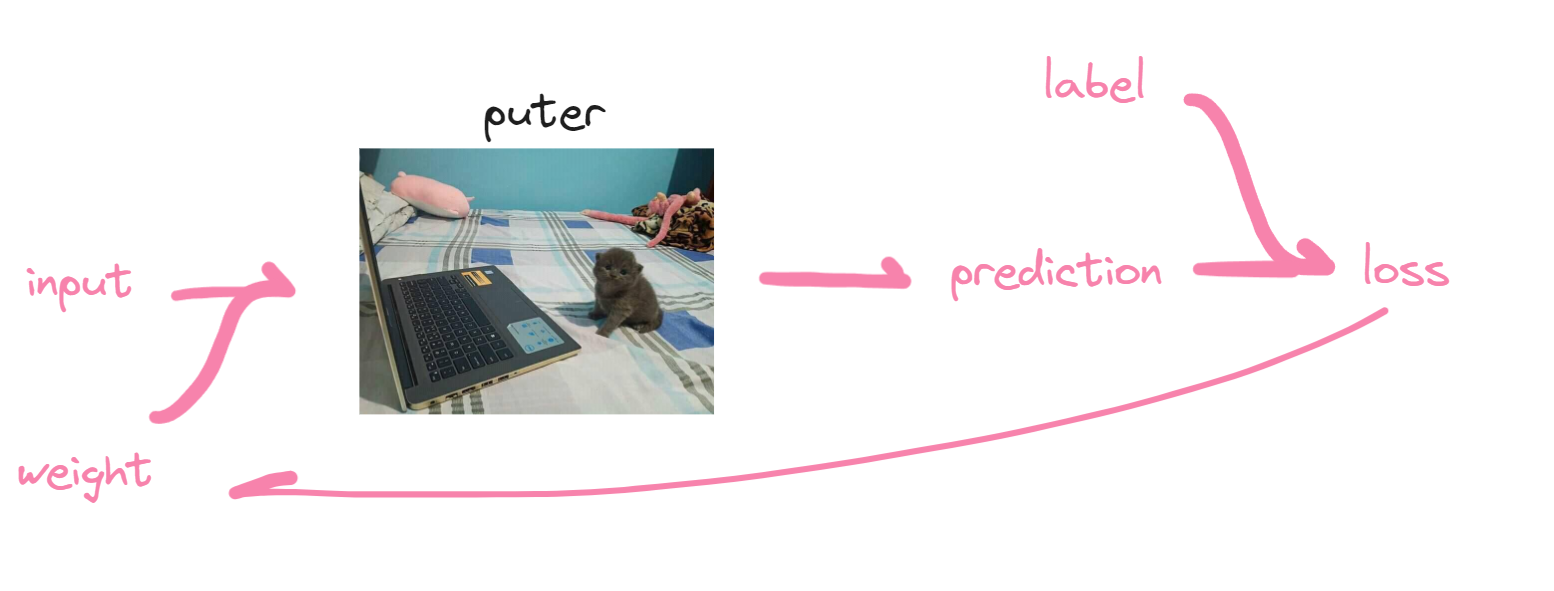
That’s basically how machine learning works through a diagram. Following this diagram, technically a machine can learn anything! Lesson 3 goes more technical, kind of like going through how to build a car from scratch, by first telling you where the materials are located and how to extract and refine them in order to use it to build a car.
what i’ve learned (lesson 3, technical)
To be technical, this is how our diagram looks like now, we will be following it from start to finish. I honestly don’t know how to structure the main info, whether to add in math, code, or just the idea, so good luck.
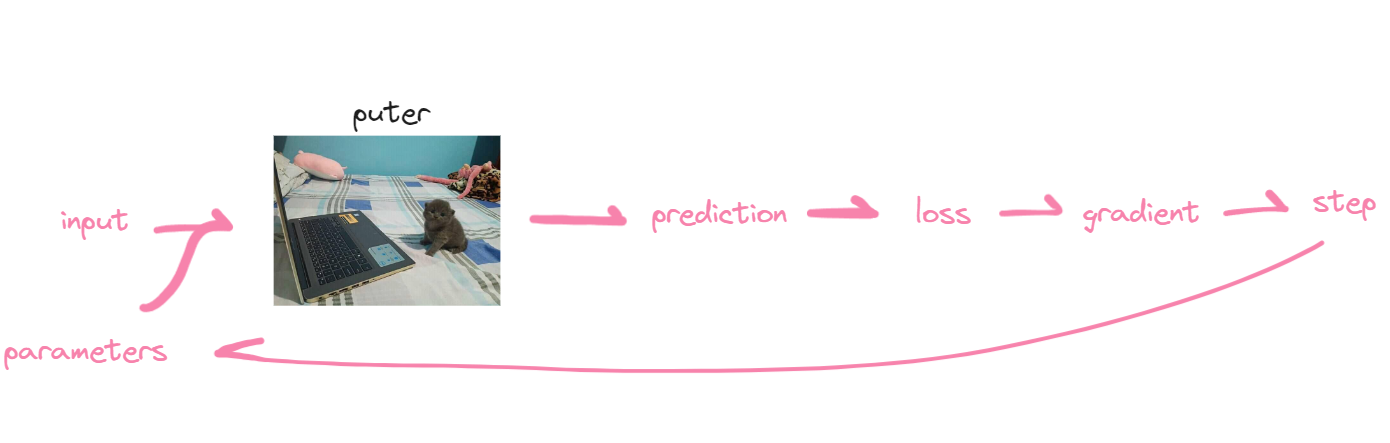
weights and parameters
To get more technical, it’s good to ask questions. Let’s start off with weights, what’s the computer value of weights? Honestly they start off random, so they don’t really matter from the start. The weights will automatically update depending on the loss.
These weights are stored in a tensor. A tensor is literally the best data structure in the world, it just holds a collection of data, but can use GPU instead of CPU. Everything is stored in tensors.
Parameters are basically variables that hold in values that are the weights.

predictions
What really is a prediction? Let’s do a 180 spin and plot a graph. This graph below literally represents a “cat.”
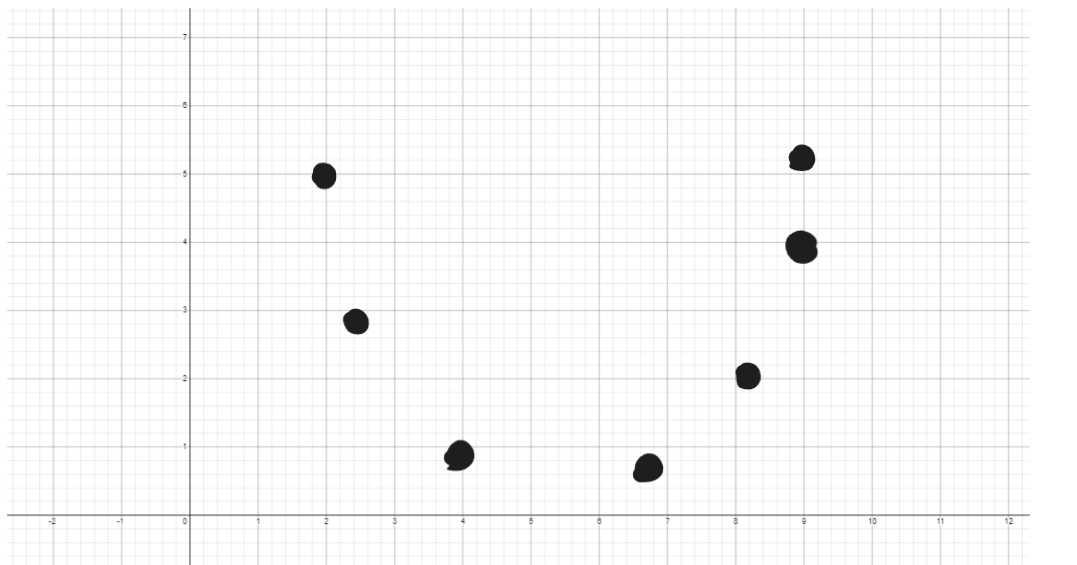
It’s scuffed but these pink dots represent a computer predicting if an input image is a cat or not. The main idea is that the closer predictions are, it would structurally fit like the black dots that represent a “cat.” As we can see, the fit is pretty bad and all over the place, so the computer needs some training.
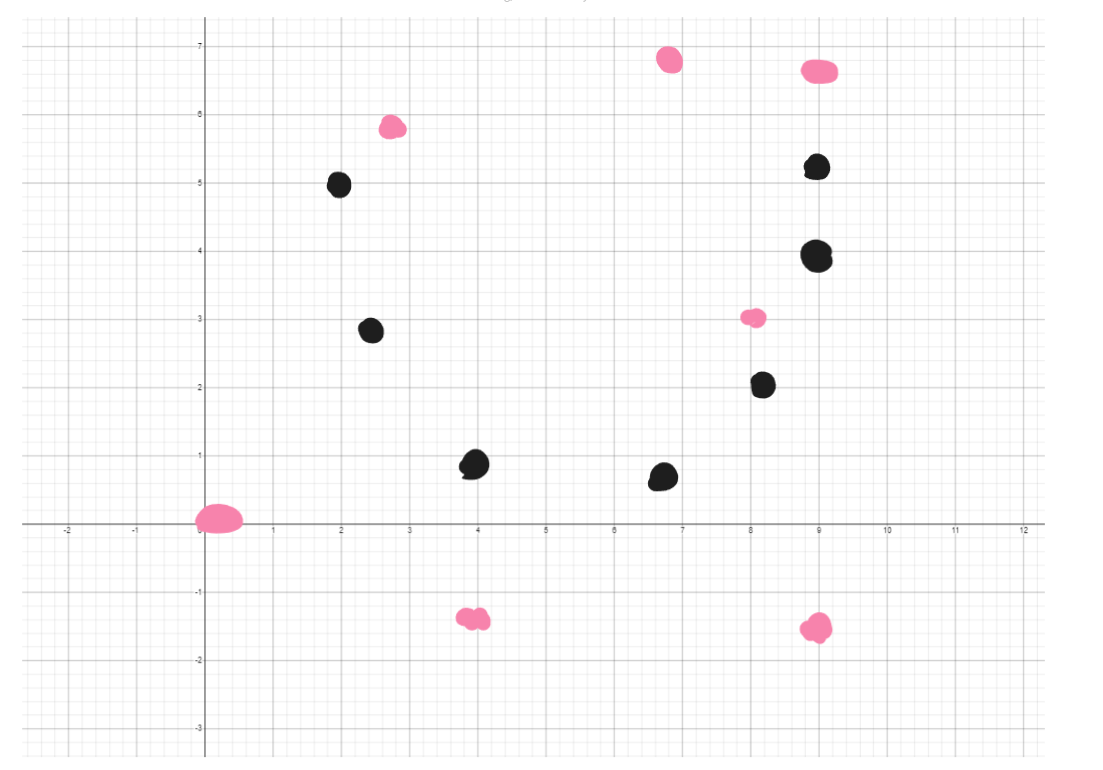
To make it all make sense, we’re creating a mathmatical function that could allow us to match the black dots. Each pink dot is a parameter in the function, and the value of that parameter is called the weight!
To make it not make sense, mathmatically this is calculated by doing matrix multipulcation! But don’t worry, we let a computer do all of this.
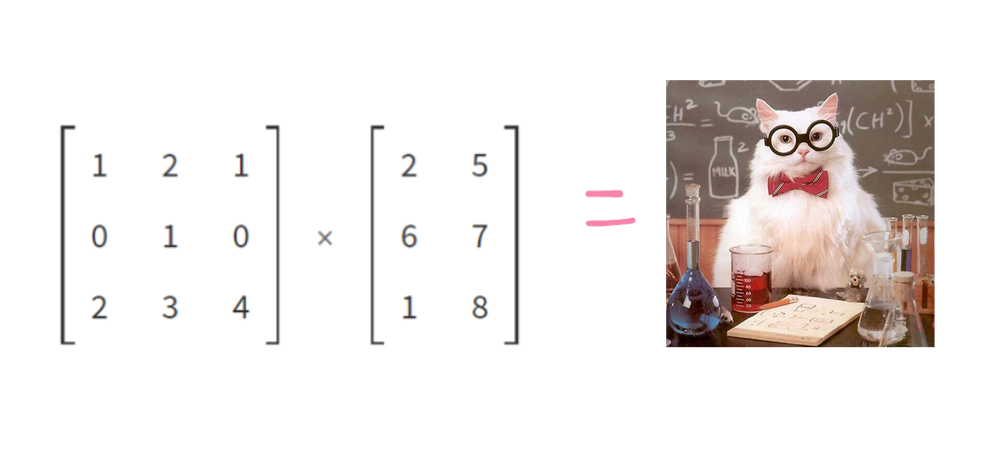
loss
How do we calculate loss? Loss can be calculated in different ways mathematically. In general it’s the difference of the “cat” represented in the graph, and the fit of the input image in the graph. The higher the loss, the worse the fit is.
If the loss is high when using a dog as an image, it’s fine, nothing needs to be changed, it’s how it should be. But if the loss is high when using a cat image, we need to fix the model by changing its weights.
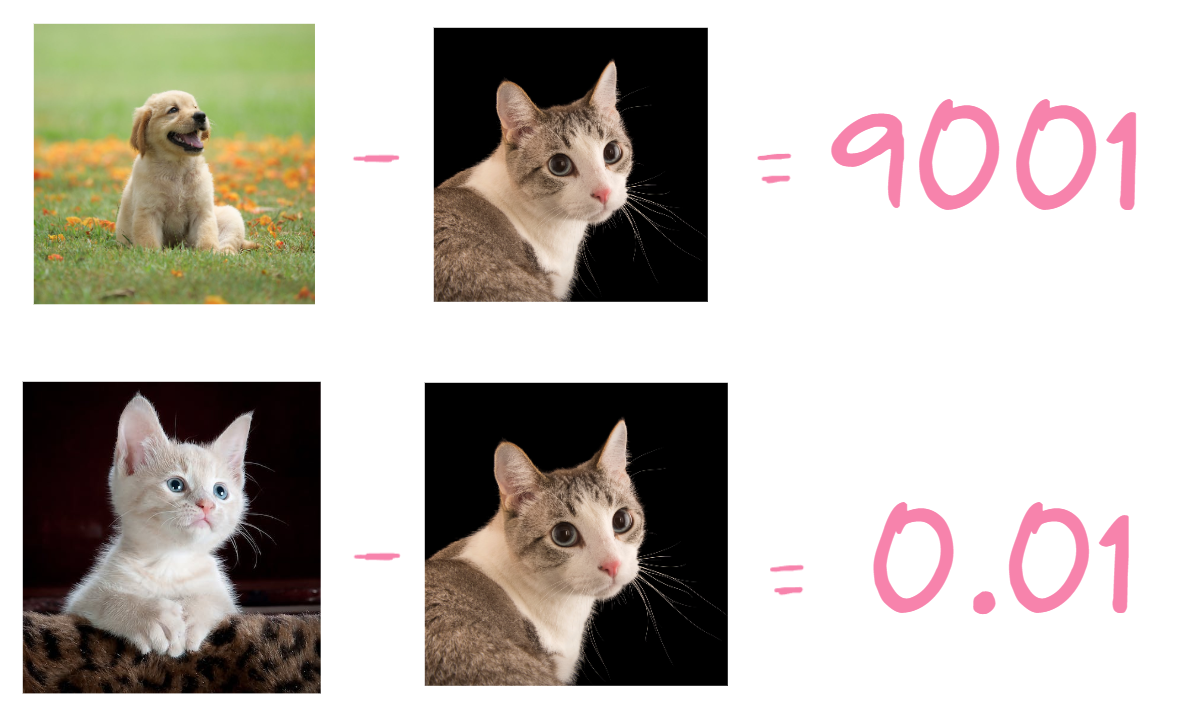
For my own practice, there are currently two ways to calculate loss that I know of, L1 norm or L2 norm. L1 norm is getting the mean absolute difference. L2 norm is getting the root mean squared error.
gradient
Gradients are what helps us with determining how to update the weights for our parameters. They’re calculated by taking the derivative of the function and solving for each parameter, high school math! It measures how the loss changes corresponding to the change of our parameter’s weight. We want low loss, so it’s best to do whatever the gradient says.

cycle
A step isn’t that important for this blog, it’s just the process of updating weights officially and doing some other things too. Each cycle/epoch the, the prediction will fit better and better in the graph. By the way, epoch is just a fancy way of saying “cycle.”
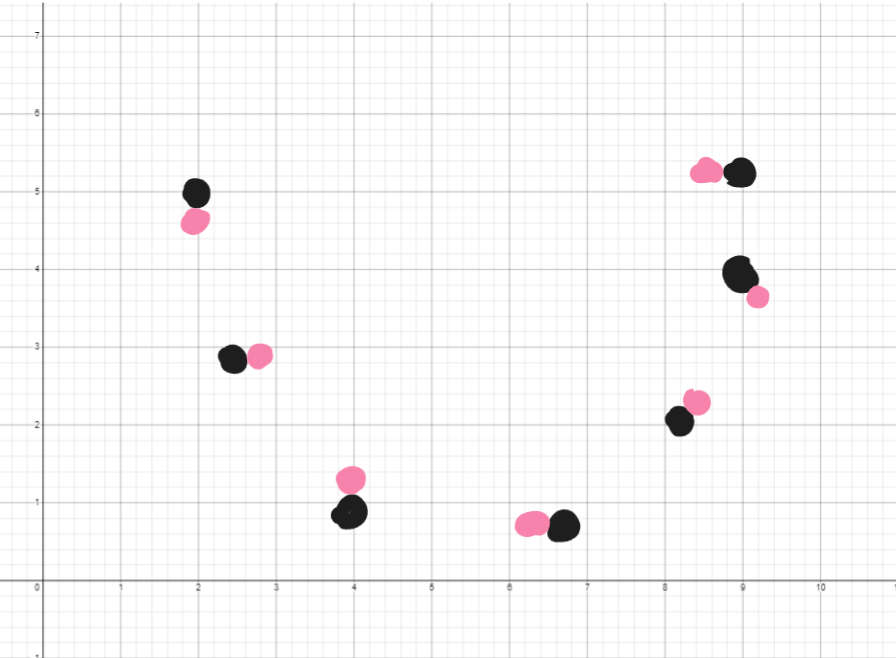
So now we’re officially done with going through everything, what they are, and what they do technically. The cycle repeats itself until the model and results are satisfactory. There are other things I’ve left out, such as ReLUs, neural nets, and sigmoids, but I think it’s okay to for the sake of this blog are are just jargon.
takeaways
I wrote this blog as a review before moving onto the next lesson. The way I want to learn is to watch the video, do an activity if there is one, read the chapter corresponding to the video lecture, then make a blog. I’m basically doing 4 epochs of the same information to get it drilled in my head like a machine.
The way I wrote this blog is experimental, not sure if I like it, not sure if it’s helpful, but it’s the first thing that came in mind to write it in this style with this content. In the future I will improve on this in any direction. But first time is a charm or something like that!
I’m excited to learn more about deep learning in the future, especially natural language processing and generation. It’s what I set out to do in the first place, so I’m excited to see an expanded vision of “how to get there.”
Anyways, I made this classification model, check it out, I’m tired. Bye.